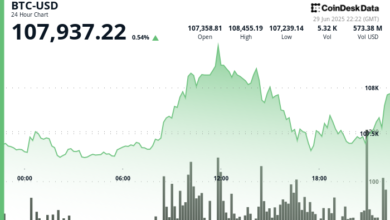
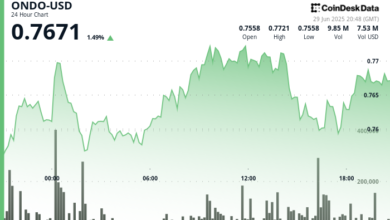
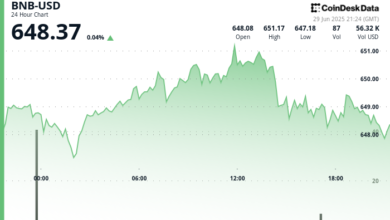
The world of artificial intelligence (AI) was taken by the storm a few days ago with the release of the Deepseek-R1, a model of reasoning that open post-training techniques in the novel. DeepSeek-R1 release not only challenged the conventional wisdom surrounding the scaling laws of foundation models-which has traditionally favored massive training budgets-but it was made in the most active research area In the field: Reasoning.
Open-weights (compared to open resources) release characteristics can easily access the AI community model, leading to an influx of clones for a few hours. Moreover, DeepSeek-R1 left its mark on the ongoing AI race between China and the United States, strengthening what is especially apparent: Chinese models are very high quality and fully capable of driving change to the original ideas.
Unlike most AI development advances, which seems to have expanded the gap between web2 and web3 in the kingdom of foundation models, the deepek-R1 release brings real implications and presents intriguing Opportunity for Web3-Ai. To assess them, we must first look at the key changes and variations of DeepSeek-R1.
Inside DeepSeek-R1
Deepseek-R1 is the result of the introduction of innovative changes to a well-established pretending framework for foundation models. In extensive terms, DeepSeek-R1 follows the same training method as most high-profile foundation models. This method consists of three main steps:
- Pretraining: The model is first pretending to predict the next word using massive amounts of data that are not adjusted.
- Administers fine tuning (SFT): This step optimizes the model in two critical areas: following the instructions and answering the questions.
- Cheating on human preferences: A final fine-tuning phase is conducted to align the model’s responses to human preferences.
Most basic foundation models – including Openai, Google, and Anthropic developed – comply with the same general process. At a high level, the Deepseek-R1 training method does not appear to be different. But somehow, instead of pretending to be a base model from the beginning, the R1 leverage its basic model of its predecessor, the Deepseek-V3-base, boasting a wonderful 617 billion parameters.
In essence, DeepSeek-R1 is the result of applying SFT to the Deepseek-V3-base with a large size reasoning. The real change lies in the construction of these reasoning datats, which is very difficult to build.
Step First: Deepseek-R1-Zero
One of the most important aspects of Deepseek-R1 is that the process does not produce a single model but two. Perhaps the most significant change of Deepseek-R1 is the creation of an intermediate model called R1-Zero, which specializes in reasoning activities. This model is trained to almost fully use reinforcement study, with a bit of reliance on label data.
Studying a ratification is a procedure in which a model is rewarded for developing the right answers, providing to generalize knowledge over time.
The R1-Zero is quite impressive, as it has been able to match the GPT-O1 with the reasoning activities. However, the model has fought in more general tasks such as answering the question and ability to read. That is.
Step Second: Deepseek-R1
The DeepSeek-R1 is designed to be a general goal model beyond reasoning, meaning it needs to exceed R1-Zero. To achieve this, the Deptseek began with its V3 model, but at this time, it was properly tune into a small dataset of reasoning.
As mentioned earlier, reasoning datasets are difficult to produce. This is where the R1-zero plays an important role. The intermediate model was used to produce a synthetic reasoning dataset, which was used to properly tone the Deepseek V3. This process resulted in another intermediate reasoning model, which was subsequently placed through a wide stage of reinforcement study using a dataset of 600,000 samples, also formed by the R1-zero. The final outcome of this process is DeepSeek-R1.
As I deleted some technical details of the R1 pretending process, here are two main takeaways:
- The R1-Zero has shown that it is possible to develop sophisticated reasoning capabilities using primary reinforcement study. Although the R1-Zero is not a powerful general model, it has successfully developed the reasoning data required for R1.
- The R1 has expanded the traditional pretiraining pipeline used by most foundation models by incorporating the R1-zero into the process. In addition, it leverages a significant amount of reasoning data generated by the R1-zero.
As a result, DeepSeek-R1 appeared as a model that corresponds to GPT-O1 reasoning capabilities while being constructed using a simpler and likely significantly cheaper pretending process.
It is all right that R1 marks an important milestone in the history of generative AI, one that is likely to reinstate the method of foundation models. When it comes to the Web3, it would be interesting to explore how the R1 influenced the emerging web3-Ai scene.
DeepSeek-R1 and Web3-Ai
To date, the web3 has been struggling to promote compelling cases of use that clearly increases the value of the creation and use of foundation models. To some extent, the traditional workflow for pretended foundation models appears to be the antisience of web3 architecture. However, despite being in its early stages, the deptseek-R1 release has highlighted many opportunities that can be naturally aligned with web3-AI architecture.
1) Study of Reinforcement Fine-Tuning Networks
The R1-Zero has shown that it is possible to develop reasoning models using pure reinforcement study. From a computational perspective, the study of reinforcement is quite similar, making it suitable for decentralized networks. Imagine a web3 network where nodes are paid for organizing a model in reinforcement study tasks, each applying different techniques. This method is more feasible than other pretending paradigns that require complex topologies of GPU and centralized infrastructure.
2) synthetic reasoning generation
Another major contribution of DeepSeek-R1 is to show the importance of synthetically generated datasets for cognitive activities. This process is also suitable for a decentralized network, where nodes perform jobs on dataset generations and are paid because these datasets are used for pretentiraining or fine-tuning foundation models. Because this data is synthetically formed, the entire network can be completely automatic without human intervention, making it an ideal fit for web3 architecture.
3) Decentralized Understanding for small distilled Reasoning models
Deepseek-R1 is a massive model with 671 billion parameters. However, almost immediately after its release, a wave of distilled reasonable models appeared, from 1.5 to 70 billion parameters. Smaller models are significantly more practical for understanding decentralized networks. For example, a 1.5B -2B distilled R1 model can be dedicated to a defi protocol or deployed inside the nodes of a depin network. Simple, we are likely to see the rise of endpoints beginning with recognition activated by decentralized compute networks. Reasoning is a domain where the performance interval between small and large models is narrow, creating a unique opportunity for the web3 that is well used these distilled models in decentralized understanding settings.
4) Verification of Reasoning Data
One of the determining features of the reasoning models is their ability to produce traces of reasoning for a given task. DeepSeek-R1 makes these traces available as part of its output output, reinforcing the importance of proven and monitoring for reasoning activities. The Internet is currently running out of outputs, with minimal visibility in the intermediate steps that lead to those results. The Web3 presents an opportunity to monitor and verify each step of reasoning, which potentially creates a “new Internet of Reasoning” in which transparency and verifiability has become the norm.
Web3-Ai had the opportunity during the Reasoning Post-R1
Deepseek-R1 release marked a point of evolution of generative AI. By incorporating wise changes to established impressing parades of pretending, it challenged traditional AI flows and opened a new AI period dedicated to reasoning. Unlike many previous foundation models, DeepSeek-R1 introduces elements that bring generative AI closer to web3.
Basic aspects of R1 – synthetic datasets of reasoning, more parallelizable training and the growing demand for monitoring – align naturally with web3 principles. While the Web3-Ai struggles to get significant traction, this new post-R1 season may show the best opportunity for the web3 to play a more significant role in the future of AI.